
INDEX
- 物流DXの第一歩は、システム導入ではなく現状診断から始まる。
- 自社の物流コスト・作業効率・在庫・配送状況などを、まず正しく把握できる状態にすることが重要。 多くの企業では、物流データが分散・属人化している。
- データは存在していても、拠点ごとに管理方法が違ったり、Excelや委託先資料に分散していたりするため、改善判断に使いにくい状態になっている。 最初に確認すべきデータは、物流コスト・人時生産性・輸配送実績・在庫精度・配送リードタイムの5つ。
- これらを整理することで、どこにムダや改善余地があるのかを判断しやすくなる。 現状診断では、チェックリストを使って自社の整備状況を確認することが有効。
- データの所在、定義、集計方法、委託先データの扱いなどを確認することで、物流DX前に整えるべき課題が見えてくる。 物流データの整理は、1拠点・1領域から小さく始めるのが現実的。
- 最初から全社一括で進めるのではなく、物流コストや人時生産性など改善効果が見えやすい領域から始め、効果を確認しながら横展開する。
はじめに:物流DXの前に、まず「今の状態」を説明できますか?
物流DXを進めたい。
物流コストを下げたい。
作業効率を上げたい。
配送や在庫の状況をもっと見えるようにしたい。
こうした課題を抱える企業は増えています。
しかし、実際に物流DXを進めようとしたとき、最初につまずきやすいのは「何を導入するか」ではありません。
それ以前に、自社の物流の現状を正しく説明できないという問題です。
たとえば、次のような問いにすぐ答えられるでしょうか。
- 物流コストは、どの拠点・どの業務で増えているのか
- 人員や作業時間に対して、どれだけの成果が出ているのか
- 拠点間移動や配送ルートにムダはないのか
- 在庫差異はどの拠点で、どの程度発生しているのか
- 配送リードタイムの遅れは、どの工程で起きているのか
これらに答えられない状態でシステムを導入しても、改善効果を判断することは難しくなります。
物流DXの第一歩は、いきなり新しいツールを入れることではありません。
まずは、自社の物流データが現状診断に使える状態になっているかを確認することです。
この記事では、物流DXを始める前に確認しておきたいデータ領域と、自社の整備状況を見直すためのチェックリストを整理します。
※物流DXは、単にシステムを導入する取り組みではありません。国土交通省でも、物流DXの推進は、物流業務の効率化や働き方改革にも関わる重要なテーマとして整理されています。だからこそ、DXを始める前には、自社の物流データが現状診断に使える状態かを確認することが重要です。
物流DXが進まない理由は「データ不足」ではなく「整理不足」にある
物流現場には、実は多くのデータが存在しています。
出荷実績、作業時間、在庫数、配送実績、車両情報、請求データ、委託先からの報告書など、日々の業務の中でさまざまな情報が記録されています。
にもかかわらず、いざ改善に使おうとすると、次のような状態になりがちです。
- データが複数のシステムやExcelに分散している
- 拠点ごとに集計方法が違う
- 担当者しか数字の意味を説明できない
- 月次集計に時間がかかり、判断が遅れる
- データはあるが、改善の優先順位を決める材料になっていない
つまり問題は、データがまったく存在しないことではありません。
多くの場合、問題は データが整理されておらず、現状診断に使える形になっていないこと にあります。
物流DXを進める前に必要なのは、まずこの状態を確認することです。
まず確認すべき5つの物流データ
物流データの整理といっても、最初からすべてのデータを完璧に揃える必要はありません。
まずは、経営判断や現場改善に使いやすい5つの領域から確認するのが現実的です。
物流DXの前に確認したいデータは、大きく5つに整理できます。すべてを一度に整える必要はありませんが、まずは自社でどこまで把握できているか確認してみましょう。
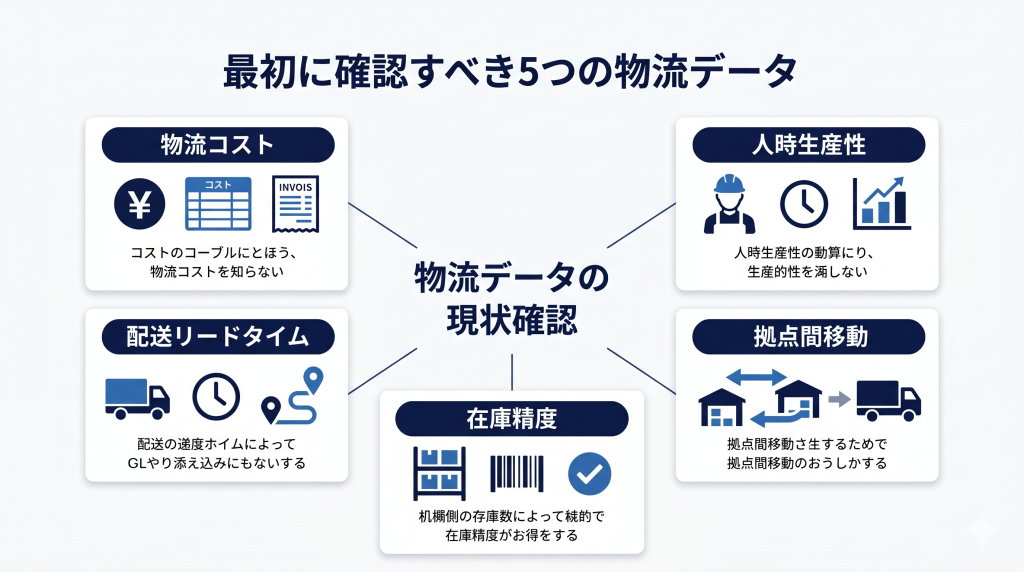
1. 物流コスト
最初に確認すべきなのは、物流コストです。
ただし、単に「物流費の総額」を見るだけでは不十分です。
重要なのは、どこで、何に、どれだけコストがかかっているのかを分解できることです。
確認したい切り口は、たとえば次のようなものです。
- 拠点別
- 荷主別
- 配送エリア別
- 業務別
- 保管費、配送費、荷役費などの費目別
物流コストの総額だけを見ている状態では、「高い」「下げたい」という話で止まりやすくなります。
一方で、拠点別や業務別に分解できると、改善すべき場所が具体的になります。
たとえば、ある拠点だけ配送費が高いのか。
特定の荷主だけ作業工数が多いのか。
保管費ではなく、実は緊急出荷や再配送がコストを押し上げているのか。
このように内訳が見えることで、改善の優先順位が判断しやすくなります。
2. 人時生産性
次に確認したいのが、人時生産性です。
人時生産性とは、かけた人員・時間に対して、どれだけの成果が出ているかを見る指標です。
物流現場では、次のような形で確認できます。
- 1人1時間あたりの出荷件数
- 1人1時間あたりのピッキング数
- 検品作業にかかった時間
- 荷役作業にかかった時間
- 繁忙期と通常期の作業効率の差
人時生産性が見えていないと、人員不足の原因が分かりにくくなります。
本当に人が足りないのか。
作業動線にムダがあるのか。
特定の工程だけ負荷が高いのか。
繁忙期の波動対応に課題があるのか。
これらを判断するには、作業実績と投入時間をセットで見る必要があります。
3. 拠点間移動・輸配送実績
物流のムダは、倉庫内だけでなく、拠点間の移動や輸配送にも発生します。
特に確認したいのは、次のようなデータです。
- 拠点間の輸送回数
- 主要ルート別の配送頻度
- 車両の積載率
- 空車・低積載の発生状況
- 配送エリアごとの負荷
拠点間移動のデータが見えていないと、配送ルートや車両台数の見直しが感覚頼みになります。
「なんとなく便数が多い」
「このルートは非効率な気がする」
「トラックが足りない気がする」
このような状態では、改善判断に説得力が出ません。
どのルートで、どれだけの頻度で、どの程度の積載率になっているのかを確認できれば、輸配送の改善余地を具体的に見つけやすくなります。
4. 在庫精度
在庫データも、物流DXの前に必ず確認しておきたい領域です。
特に重要なのは、帳簿上の在庫と実際の在庫がどれだけ一致しているかです。
確認したい項目は、次のようなものです。
- 在庫差異率
- 棚卸頻度
- 欠品発生件数
- 過剰在庫の発生状況
- 拠点別・商品別の差異傾向
在庫精度が低いと、欠品、過剰在庫、緊急出荷、誤出荷などの原因になります。
また、在庫データに信頼性がない状態では、自動化や需要予測の精度も上がりにくくなります。
物流DXを進める前に、まず在庫情報がどの程度正確に管理されているかを確認することが大切です。
5. 配送リードタイム
最後に確認したいのが、配送リードタイムです。
配送リードタイムは、単に「出荷から到着までの日数」だけを見るのではなく、工程ごとに分解して確認することが重要です。
たとえば、次のような切り口です。
- 受注から出荷指示まで
- 出荷指示からピッキング完了まで
- 検品から出荷まで
- 出荷から納品まで
- 配送遅延が発生した工程
リードタイムを分解できないと、遅れの原因が分かりません。
倉庫内作業が遅れているのか。
出荷指示が遅いのか。
配送ルートに問題があるのか。
委託先との連携に課題があるのか。
工程ごとに見える状態にすることで、改善すべきポイントが明確になります。
自社の物流データ現状診断チェックリスト
ここからは、自社の物流データが現状診断に使える状態かを確認するためのチェックリストです。

物流コストに関するチェック
- 物流コストを総額だけでなく、拠点別に分解できる
- 荷主別・サービス別のコストを確認できる
- 保管費、配送費、荷役費など費目別に整理できている
作業・人時生産性に関するチェック
- 作業時間と作業実績をセットで確認できる
- 人時生産性を月次で追える
- 繁忙期と通常期の生産性の違いを比較できる
輸配送・拠点間移動に関するチェック
- 主要ルートごとの輸送回数を把握できる
- 車両の積載率を区間別に確認できる
- 空車・低積載の発生状況を確認できる
在庫・品質に関するチェック
- 在庫差異率を拠点別に確認できる
- 欠品や過剰在庫の発生傾向を把握できる
- 棚卸結果を改善活動に活用できている
配送リードタイムに関するチェック
- 受注から納品までのリードタイムを分解できる
- 遅延がどの工程で発生しているか確認できる
- サービスレベル別に配送状況を確認できる
データ運用に関するチェック
- 拠点ごとにデータの定義が揃っている
- 委託先の実績データを自社で使いやすい形に整理できる
- 集計作業が特定の担当者に依存していない
- 必要なデータを短時間で取り出せる
- データをもとに改善の優先順位を決められている
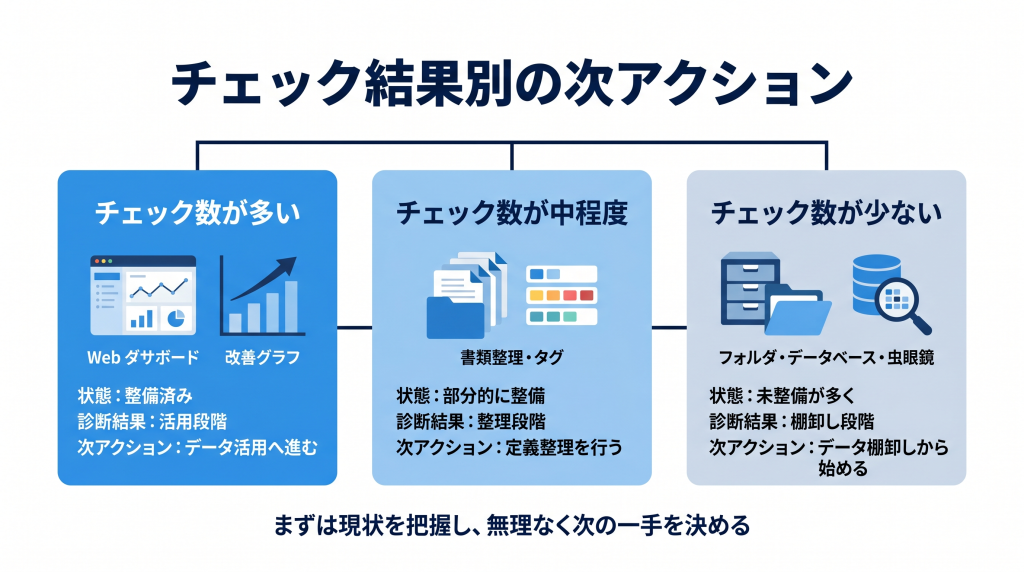
チェック結果の見方
15個以上チェックがついた場合
物流データの整備は比較的進んでいます。
次のステップは、データを改善活動や投資判断にどう活かすかです。
すでに見えている数字をもとに、改善テーマの優先順位を整理し、効果検証の仕組みを整える段階にあります。
10〜14個チェックがついた場合
一部のデータは整理されていますが、まだ現状診断としては不十分な可能性があります。
特に、拠点ごとの定義違いや、委託先データの扱いに注意が必要です。
まずは、データの粒度や集計ルールを揃えることから始めるとよいでしょう。
9個以下の場合
物流DXの前に、現状診断のためのデータ整備を優先すべき状態です。
システム導入を急ぐよりも、まずはどのデータがどこにあり、何が不足しているのかを棚卸しすることが重要です。
1拠点・1領域に絞って、物流コストや人時生産性など、改善効果が見えやすい領域から始めるのがおすすめです。
よくある「見えない物流データ」の状態
チェックリストを確認すると、自社の課題が少し見えやすくなります。
ここでは、多くの企業で起きやすい状態を整理します。
状態1:数字はあるが、比較できない
拠点ごとに出荷件数や作業時間を集計していても、定義が違うと比較ができません。
同じ「出荷件数」でも、伝票単位で数えている拠点と、商品単位で数えている拠点があれば、単純比較はできません。
まずは、指標の定義を揃えることが必要です。
状態2:データが担当者の手元にある
Excelや個別資料で管理されているデータは、担当者がいる間は問題なく見えることがあります。
しかし、担当者が不在になると、どこに何があるか分からなくなるケースもあります。
属人化したデータ管理は、現状診断の大きな妨げになります。
状態3:月次でしか分からない
月次集計は重要ですが、物流現場では日々状況が変わります。
月末にならないと問題が見えない状態では、改善のタイミングが遅れます。
すべてをリアルタイム化する必要はありませんが、重要な指標については週次や日次で確認できる仕組みがあると、改善につなげやすくなります。
状態4:委託先のデータがバラバラ
自社内のデータはある程度整理できていても、委託先からの報告形式がバラバラだと、全体像が見えにくくなります。
PDF、Excel、メール本文、紙の報告書などが混在している場合は、自社側で使いやすい形式に揃えるルールづくりが必要です。
※物流データが整理されていないと、経営判断や現場改善に必要な数字をすぐに確認できません。物流データを経営と現場の共通認識につなげる考え方については、関連記事の経営と現場の分断が物流改革を止める理由でも詳しく解説しています。
物流DXの進め方がわかる
最初の一歩は「1拠点・1領域」で十分
物流データを整理するとなると、全社一括で大きなプロジェクトを想像しがちです。
しかし、最初からすべてを整える必要はありません。
むしろ、最初は小さく始める方が現実的です。
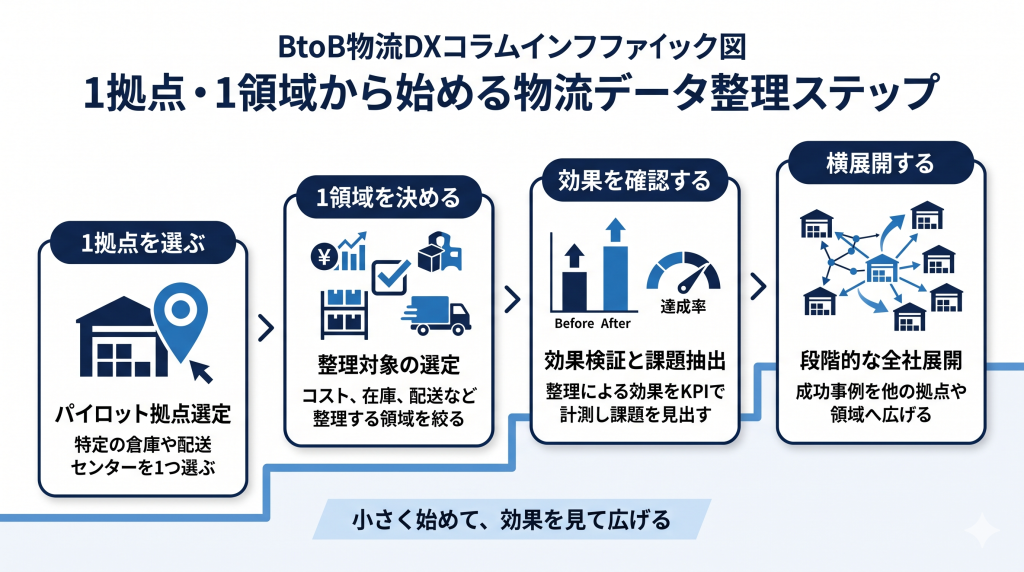
おすすめは、1拠点・1領域から始めることです。
たとえば、次のような始め方です。
- まず1拠点だけ物流コストを分解する
- 1つの工程だけ人時生産性を確認する
- 主要ルートだけ積載率を確認する
- 1カテゴリの商品だけ在庫差異を確認する
- 特定の配送サービスだけリードタイムを分解する
範囲を絞ることで、現場負担を抑えながら、データ整備の効果を確認できます。
小さく始めて、効果が見えたら横展開する。
この進め方の方が、社内合意も取りやすくなります。
現状診断から改善につなげる進め方
物流データの現状診断は、チェックして終わりではありません。
重要なのは、診断結果を改善につなげることです。
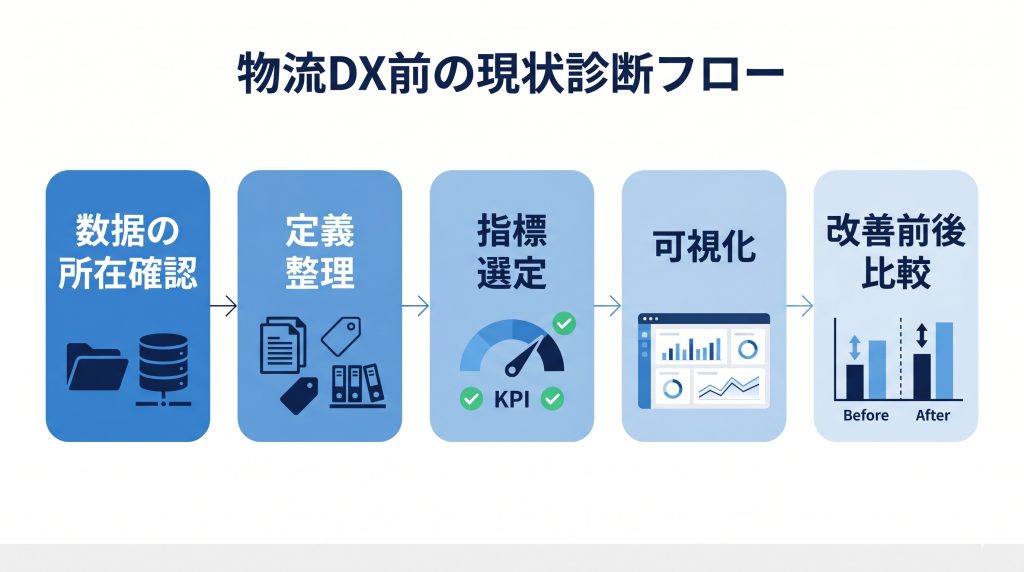
STEP1:データの所在を確認する
まずは、必要なデータがどこにあるかを確認します。
WMS、配車システム、基幹システム、勤怠管理、Excel、委託先資料など、データの置き場所を洗い出します。
STEP2:データの定義を揃える
次に、指標の意味を揃えます。
出荷件数、作業時間、待機時間、在庫差異、配送遅延など、よく使う指標の定義を明確にします。
ここを曖昧にしたまま進めると、後から数字の解釈がズレます。
STEP3:改善に使う指標を絞る
すべてのデータを見る必要はありません。
最初は、改善判断に使う指標を絞ります。
物流コスト、人時生産性、積載率、在庫差異率、配送リードタイムなど、目的に応じて優先順位を決めます。
STEP4:小さく可視化する
最初から立派なダッシュボードを作る必要はありません。
まずは、Excelや簡易レポートでも構いません。
大切なのは、数字を見て判断できる状態をつくることです。
STEP5:改善前後を比較する
最後に、改善前と改善後の変化を確認します。
データ整備の目的は、数字を集めることではありません。
改善前後を比較し、次にどこを改善すべきか判断できる状態にすることです。
まとめ:物流DXの前に、自社のデータを診断する
物流DXを始める前に必要なのは、最新システムの選定ではありません。
まず確認すべきなのは、自社の物流データが現状診断に使える状態になっているかです。
物流コスト、人時生産性、拠点間移動、在庫精度、配送リードタイム。
これらのデータが、必要な粒度で確認できるか。
拠点ごとに比較できるか。
委託先のデータも含めて把握できるか。
改善前後を比較できるか。
この確認をしないままDXを進めると、導入後に「何が良くなったのか分からない」という状態になりかねません。
まずは、自社の物流データを棚卸しすること。
そして、1拠点・1領域から小さく現状診断を始めること。
それが、物流DXを現実的に進めるための第一歩です。
※物流データを現場改善や投資判断に活用するには、倉庫内や輸配送の状況を一元的に把握できる仕組みづくりが欠かせません。株式会社PALでは、物流現場のデータ活用や改善に関する情報を物流DXコラムで発信しているほか、輸配送の見える化を支援するDTSなどを通じて、物流データの整理・活用を支援しています。
FAQ
Q1. 物流DXは何から始めるべきですか?
まずは、自社の物流データが現状診断に使える状態かを確認することから始めるのがおすすめです。システム導入より前に、物流コスト、人時生産性、在庫精度、配送リードタイムなどのデータがどこまで整理されているかを確認する必要があります。
Q2. 物流データの可視化には大規模なシステムが必要ですか?
必ずしも必要ではありません。最初は1拠点・1領域に絞り、Excelや既存システムのデータを整理するところから始めることも可能です。重要なのは、数字を改善判断に使える状態にすることです。
Q3. どのデータから確認すればよいですか?
最初は、物流コストと人時生産性から確認すると進めやすいです。経営判断にも現場改善にもつながりやすく、改善効果を説明しやすい領域だからです。
Q4. 委託先のデータも現状診断に含めるべきですか?
はい。3PLや運送会社など外部委託の比率が高い場合、委託先のデータを含めないと物流全体の実態が見えにくくなります。報告形式を揃え、自社で使いやすい形に整理することが重要です。
Q5. チェックリストで項目が少なかった場合、何をすればよいですか?
まずは、データの所在を洗い出すことから始めます。どのデータがどこにあり、誰が管理していて、どの形式で取り出せるのかを確認します。そのうえで、1拠点・1領域に絞ってデータ整理を進めるとよいでしょう。


