INDEX
「入れたのに使われない」を避けるための、業務目的・データ粒度・更新頻度・権限・運用体制の5軸整理
はじめに
「データ統合基盤を入れたのに、現場でうまく使われない」。これは物流業界でしばしば起きる事象です。
理由は基盤そのものの性能ではなく、自社の業務目的・データ粒度・運用体制との噛み合わせにあります。データ統合基盤は、入れること自体が目的ではなく、現場で判断に使われて初めて効果が出る仕組みです。
本記事では、データ統合基盤とは何かを定義したうえで、物流現場で活かすために必要な5つの判断軸を整理します。導入前後のどちらの段階でも、自社の運用を点検する材料として使える内容にしています。
物流DXの進め方がわかる
- データ統合基盤とは、複数システムのデータを1か所に集約し判断に使える形に整える仕組みである
- 物流現場における基盤の本質は、データを集めることではなく判断の前提を揃えることである
- 既存システムを残したまま統合層を被せる構成も、データ統合基盤として有効である
- 活かされない3つの理由は、業務目的の後付け・データ粒度のズレ・運用体制の曖昧さである
- 成否はツールの選定より前段にあり、5つの判断軸を最初に設計しているかで決まる
- 判断軸1は業務目的、対象を1〜3個に絞ることで必要なデータと粒度が決まる
- 判断軸2はデータ粒度、経営層と現場で必要粒度が違うため複数ビューが現実的である
- 判断軸3は更新頻度、リアルタイムが常に正解ではなく判断の頻度に合わせる
- 判断軸4は権限、荷主別・案件別の閲覧範囲を最初に設計しないと運用で停滞する
- 判断軸5は運用体制、業務オーナーと技術オーナーの2人体制が継続更新の鍵である
1. データ統合基盤とは|物流現場での意味
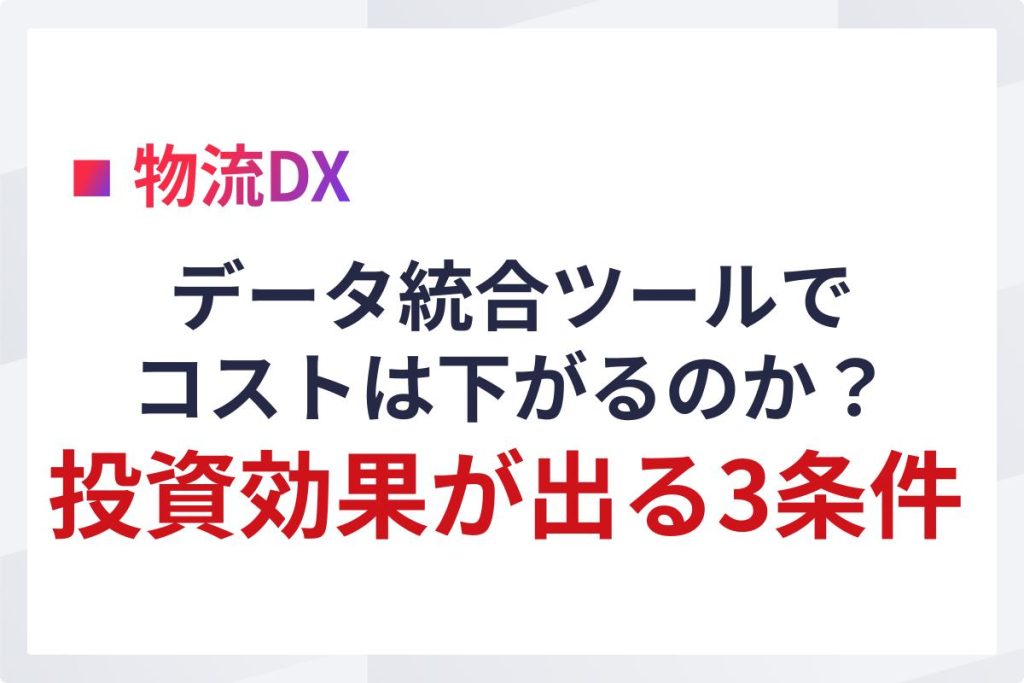
結論:データ統合基盤とは、複数システムのデータを1か所に集約し、判断に使える形に整える仕組みのことです。
データ統合基盤は、WMS、配車システム、勤怠システム、運賃計算システムなど、業務ごとに分断していたデータを横断的に束ねる役割を持ちます。基盤と呼ばれるのは、その上にダッシュボード、BI、分析、AI活用などのレイヤーが乗るためです。
物流現場におけるデータ統合基盤の本質は、データの倉庫を作ることではありません。判断に使う数字を、同じ前提・同じ粒度・同じタイミングで揃えることが目的です。同じ「在庫数」でも、システムごとに更新タイミングが違えば、議論の前提が崩れます。
また、データ統合基盤は一気通貫の大規模システムである必要はありません。既存システムを残したまま、上に統合層を被せる構成も基盤と呼べます。重要なのは構造より、判断の根拠が揃うかどうかです。
物流現場でよく見られる『データが分断したまま』の状態
- 配車表はExcel、運賃はWMSの帳票、勤怠は別システムで、突き合わせが手作業
- 拠点別・荷主別の採算が、月次の経理レポートまで待たないと見えない
- KPIの数字が部門ごとに異なる定義で集計されており、会議で噛み合わない
- 外部報告用の数字を作るたびに、複数システムから手作業で抜き出している
こうした状態は珍しくなく、現場が悪いわけではありません。長年の運営の積み重ねで自然に発生する構造です。
2. データ統合基盤を物流現場で活かしきれない3つの理由
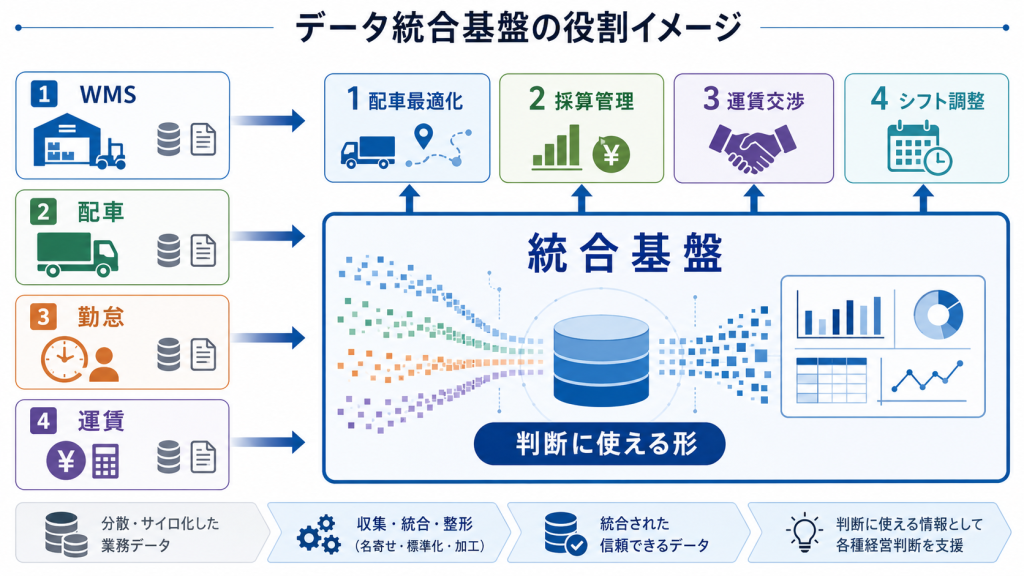
結論:データ統合基盤が活かされないのは、基盤の性能ではなく、目的・粒度・運用の3点のズレが残っているためです。
導入したのに使われない、あるいは使われ方が広がらないケースには、よく似たパターンがあります。3つに分けて整理します。
理由1|業務目的が後付けになっている
「データを全部集めてから、何に使うかを考える」進め方になると、現場が活用する場面がはっきりせず、運用が止まります。
データを集めることと、判断に使うことは別の活動です。最初に「どの判断に使うか」を決めずに進めると、ダッシュボードはあるが見られない状態が定着します。
理由2|データ粒度が現場の判断と合っていない
経営層向けに集計された粗い粒度では、現場の改善判断には使えません。逆に、現場のトランザクション全件を扱うと、経営層の論点が見えなくなります。
同じ基盤でも、使う立場で必要な粒度は違います。粒度を分けずに1階層で運用しようとすると、どちらにも使われない中途半端な数字が並びます。
理由3|運用体制が誰のものか曖昧
情報システム部門が作って、現場が見るだけの体制にすると、データ定義の改善が止まります。荷主や案件が変わるたびに必要な数字も変わるため、運用は継続的に更新が必要です。
基盤は導入で終わりではなく、運用で進化します。誰がオーナーで誰が更新するかが明確でないと、3か月で陳腐化します。
物流DXの進め方がわかる
お役立ち資料を無料でダウンロード
3. 「使われる基盤」と「使われない基盤」を分けるもの
結論:使われる基盤になるかは、ツールではなく、5つの判断軸を最初に設計しているかで決まります。
データ統合基盤の成否は、製品選定よりも前段にあります。導入前に、自社が何のために集めるか、どこまでの粒度で見るか、誰が運用するかを決めておくことで、入れた後の活用が決まります。
変えるもの/変えないもの
変えないもの:既存システムの存在、現場の運用ノウハウ、業務プロセスの根本。基盤は既存の上に被せる前提で考えます。
変えるもの:判断の根拠、データ定義、月次の会議で見る数字、横展開のスピード。これらを統合基盤の上に乗せ替えていきます。
誤解されやすい点を先に解いておく
- 誤解1:高機能なツールを選べば成功する → 違います。判断軸の設計が先です。
- 誤解2:全社のデータを最初から集める必要がある → 違います。判断に使う領域から始めます。
- 誤解3:リアルタイムが常に正解 → 違います。判断の頻度に合わせます。
- 誤解4:基盤は情報システム部門のもの → 違います。業務オーナーと共同運用です。
これらの誤解を先に整理しておくことで、社内の合意形成と運用設計が早く進みます。
4. 物流現場で活かす5つの判断軸

結論:データ統合基盤を物流現場で活かすには、業務目的・データ粒度・更新頻度・権限・運用体制の5軸を最初に決めることが必要です。
5つの判断軸は、導入前にも、運用見直し時にも使えます。1軸ずつ整理します。
判断軸1|業務目的(何の判断に使うか)
最初に決めるのは、基盤が支える判断です。配車最適化、荷主別採算管理、運賃交渉、シフト調整、在庫差異管理など、対象を1〜3個に絞ります。
判断対象が決まると、必要なデータと粒度が自動的に決まります。逆に判断対象が決まらないと、何でも集めるだけの倉庫になります。
注意点:「全部の判断に使いたい」が出てきますが、最初は絞ります。広げるのは運用が定着してからです。
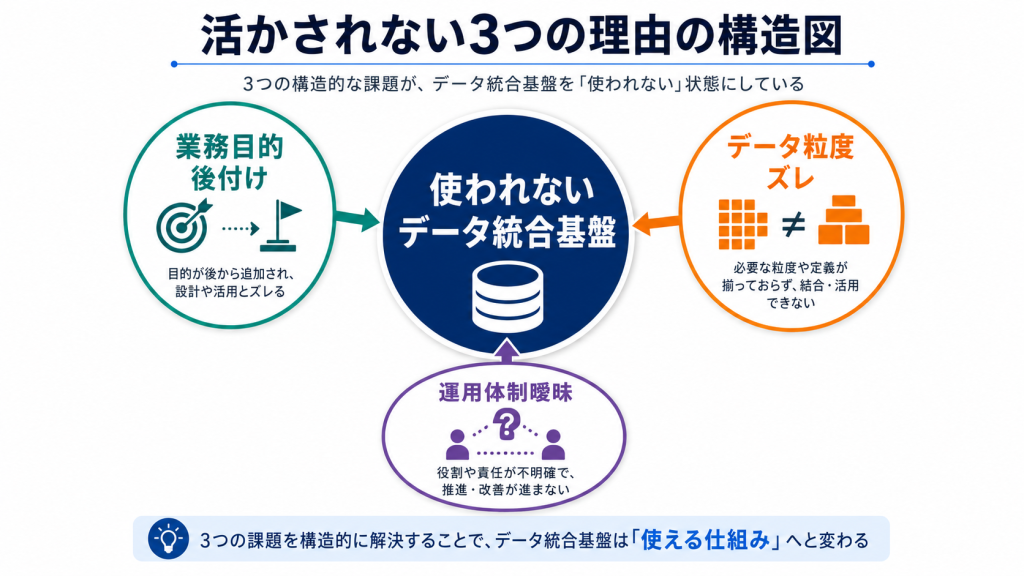
判断軸2|データ粒度(どこまで細かく見るか)
経営層は拠点別・月次の粒度、現場は日別・案件別の粒度で見たい場合が多くあります。粒度を分けて、同じ基盤の上に複数のビューを作る設計が現実的です。
粒度が合わないと、会議で「数字が違う」が起こります。同じ基盤から派生したビューであることを明示することで、論点が数字の正しさから判断の方向性に移ります。
判断軸3|更新頻度(いつ反映されるか)
リアルタイム連携が常に必要なわけではありません。配車前の確認は日次でも回り、月次の採算管理は月次更新で十分なケースもあります。
更新頻度を上げるほど、システム連携の難易度と運用コストが上がります。判断の頻度に合わせた更新設計が、コスト面でも運用面でも合理的です。
判断軸4|権限(誰が何を見られるか)
荷主別の採算データ、ドライバー別の稼働データ、運賃データなどは、社内でも閲覧範囲を分ける必要があります。権限設計を後回しにすると、運用開始後に閲覧範囲の調整で停滞します。
権限は、業務単位だけでなく、拠点単位・荷主単位・案件単位の組み合わせで設計します。最初に大まかな方針を決めておくと、後の運用が安定します。
判断軸5|運用体制(誰がオーナーで誰が更新するか)
業務オーナー(業務側)と技術オーナー(情報システム側)の2人を最低限置きます。業務オーナーがデータ定義の判断を行い、技術オーナーが実装と保守を担う分担です。
運用体制が決まっていないと、データ定義の追加・変更の意思決定者が不在になり、基盤の進化が止まります。導入直後の3か月で運用ルールを定着させることが鍵です。
5. データ統合基盤の導入・見直し前に確認すべき項目
結論:最初に確認すべきなのは、自社のどの判断にデータが足りていないかと、既存システムから取れるデータの実態です。
5つの判断軸を埋める前に、自社の現状を確認しておくと、判断軸の設定が現実的になります。
- 判断不足マップ:今どの判断でデータが足りずに困っているかを書き出す
- 既存システム棚卸し:WMS・配車・勤怠・運賃の保有データと出力可否を整理
- KPI定義の統一状況:拠点間・部門間で同じ定義になっているかを確認
- レポート作成負荷:手作業集計に毎月何時間使っているかを定量化
- 業務オーナー候補:5軸の業務目的を判断できる人物が社内にいるか確認

なぜ確認するのか。基盤導入後の運用は、社内の判断者と既存資産で決まるためです。確認を飛ばすと、ツール選定で時間を使っても、運用で止まります。
確認は2〜3週間程度で十分です。長期間の調査をしてから始めるより、最低限の現状把握で着手する方が、結果として早く効果が出ます。
まとめ|データ統合基盤の成否は、5つの判断軸を最初に決めるかで決まる
データ統合基盤とは、複数システムのデータを1か所に集約し、判断に使える形に整える仕組みです。物流現場では、配車・採算・運賃・在庫など、分断しているデータを束ねる役割を持ちます。
ただし、入れただけでは効果は出ません。業務目的、データ粒度、更新頻度、権限、運用体制の5つの判断軸を最初に決めておくことで、「使われない基盤」になることを避けられます。
導入済みの基盤でも、5軸の観点で運用を見直すことで、活用度を上げられます。基盤は導入で終わりではなく、運用で進化する性質を持ちます。
株式会社PALでは、データ統合基盤の判断軸整理や、既存基盤の活用度診断についてご相談を受け付けています。営業提案ではなく、現状整理の入り口としてお気軽にご活用ください。
物流DXの進め方がわかる
お役立ち資料を無料でダウンロード
FAQ
Q1. データ統合基盤とデータレイクは違いますか?
データレイクはデータを蓄積する保管庫を指し、データ統合基盤は判断に使うために整える仕組みを指します。両者は一部重なりますが、データ統合基盤は『判断に使える形』を含む点が中心的な違いです。
Q2. 既存システムを置き換える必要がありますか?
必須ではありません。既存システムを残したまま、データを取り出して統合層で束ねる構成が現実的です。リプレイス前提だと初期投資と運用切り替えコストが大きくなります。既存システムのデータ出力可否を先に確認します。
Q3. 5つの判断軸はどの順番で決めるべきですか?
業務目的→データ粒度→更新頻度→権限→運用体制の順が基本です。業務目的が決まらないと粒度も頻度も決まらないため、最初に対象判断を1〜3個に絞ります。
Q4. リアルタイム連携は必要ですか?
判断の頻度によります。配車前確認や倉庫内オペレーションは日次で十分なケースが多く、リアルタイムを求めるとシステム連携の難易度とコストが上がります。判断頻度に合わせて選びます。
物流DXの進め方がわかる
お役立ち資料を無料でダウンロード
関連して、「労働集約型から抜け出すデータ集約型への転換3ステップ」「物流DX前の現状診断チェックリスト」も参考になります。経営層への説明には、「物流投資ROIの測り方|CLOが取締役会に示す4つのデータ」もあわせて確認すると有効です。
また、物流DXの方向性は、国土交通省の「物流分野におけるDXの取組」も一次情報として参考になります。